
After Lilac Joins Databricks to Simplify Unstructured Data Evaluation for Generative AI, let’s see what is new and what it brings to organizations and data.
A little about Lilac – Databricks made an exciting announcement on March 19th, revealing their partnership with Lilac, an innovative platform designed to empower data scientists in navigating, clustering, and dividing diverse text datasets, particularly improving generative AI capabilities. Lilac stands out for its scalability and intuitive interface, catering to various applications, from analyzing large language models (LLMs) outputs to refining unstructured data for robust model training.
Integrating Lilac’s tools with Databricks represents a major advancement for clients seeking to accelerate the creation of superior generative AI applications using their own company data.
Data Exploration and the Challenges in the GenAI
Understanding and exploring data are fundamental steps in adapting the capabilities of large language models (LLMs) and other generative AI technologies. Data is the core of various processes, including model training, output evaluation, and data curation for Retrieval-Augmented Generation (RAG).
Traditional methods of analyzing unstructured text data have long been characterized by manual, labor-intensive approaches that lack scalability. These complexities consume significant time and threaten many practitioners, discouraging them from boarding on the exploration journey. Solving these difficulties in the context of generative AI services is essential, where data volume and complexity will only increase.
Databricks and Unstructured Data
The collaboration between Databricks and unstructured Data offers a powerful solution to these challenges. Databricks brings scalable computing power, a unified data lakehouse architecture, and a comprehensive machine learning and analytics tool suite. On the other hand, Unstructured specializes in simplifying the intricate process of ingesting, comprehending, and preprocessing unstructured data from diverse sources. Together, they work harmoniously to convert raw, disorganized data into a structured asset, primed to unleash insights that propel innovation and foster growth.
Databricks and the need for open LLMs
Databricks now came with DBRX, a new open large language model that is versatile and breaks performance and efficiency records in response to the need for open LLMs. The announcement continues the current practice of creating open and broad language models customized for business use.
What is DBRX?
The Mosaic Research team of Databricks developed the open-source DBRX large language model. Constructed as a Mixture-of-Experts model, DBRX can attain exceptional processing speed efficiency without sacrificing model functionality. It balances speed and quality by operating with 36 billion of the 132 billion characteristics available at any moment.
Databricks demonstrated DBRX’s performance against other LLMs by revealing figures demonstrating the model outperforming OpenAI’s GPT-3.5 and other open-source models on various common benchmarks.
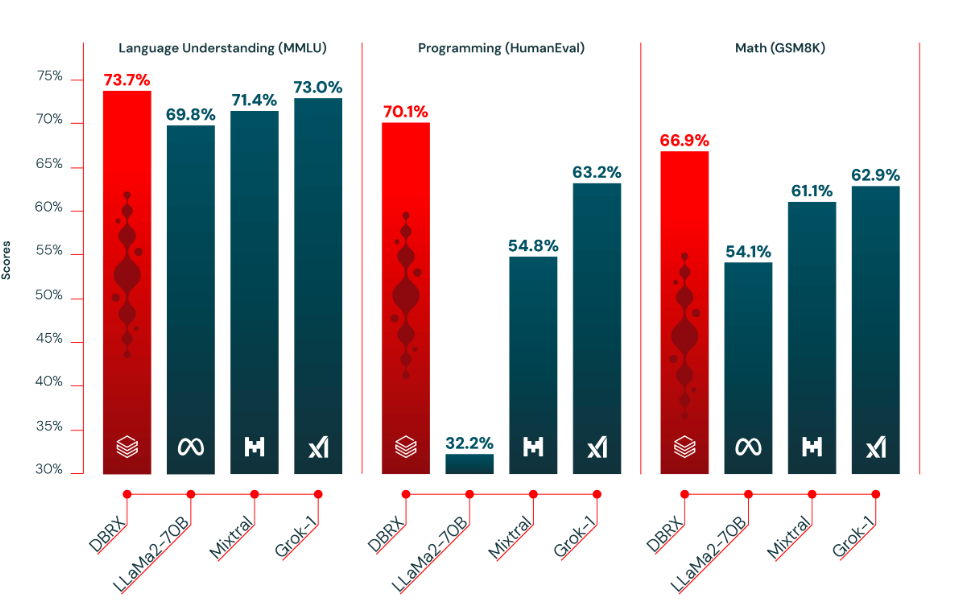
Image source: databricks.com /blog/introducing-dbrx-new-state-art-open-LLM
Databricks highlights DBRX’s adaptability, empowering enterprises to build AI applications customized to their data and needs. With its open-source license, companies can modify DBRX to suit their specific requirements, potentially enhancing performance compared to closed models.
Smooth Integration with Databricks
DBRX was built entirely within the Databricks platform, utilizing tools like Unity Catalog for data governance, Apache Spark for data processing, and Mosaic AI Training for model refinement. This comprehensive integration maximizes the solution’s overall value.
Databricks offers tools and infrastructure for customers to pre-train their DBRX-class models from scratch or to continue training using Databricks-provided checkpoints. This adaptability enables organizations to customize the model’s capabilities to meet enterprise-specific requirements.
Analyst’s Perspective
The launch of DBRX reflects the growing trend of open LLMs, enabling enterprises to customize the technology to suit their unique environments. This aligns with recent releases such as Meta’s LLaMa models, Google’s Mistral, and EleutherAI’s GPT-Neo and GPT-J LLMs. DBRX enters a market dominated by commercial solutions from companies like OpenAI and Anthropic.
DBRX’s employment of the MoE architecture balances high performance and efficient processing speed, effectively tackling the resource-intensive operations that often hinder AI model deployment. This feature positions DBRX as a potent tool for various AI tasks and a financially feasible choice for various enterprises.
For Enterprises
Utilizing DBRX through Databricks provides enterprises a continuous route to integrating advanced AI capabilities into their operations. The model’s language understanding and code generation proficiency prove beneficial for automating tasks, enhancing data analysis, and refining decision-making processes. This aligns with Databricks’ long-standing excellence in this domain.
Expanding Opportunities through Open Source
By open-sourcing DBRX, Databricks unlocks opportunities for the global AI research community to enhance and expand upon the model. Leveraging this collective expertise, Databricks can further improve DBRX, nurturing a dynamic ecosystem around its AI technologies.
The success of DBRX in the broader market hinges on how easily organizations can integrate and tailor the model for their specific needs. Databricks must prioritize robust support and resources to facilitate widespread adoption.
DBRX’s release underscores Databricks’ dedication to democratizing AI while establishing new model performance, customization, and efficiency standards. This initiative has the potential to catalyze more widespread and impactful AI adoption across industries, driving the next wave of AI-enabled transformation—a testament to Databricks’ mission to deliver data intelligence to every enterprise.
Why Choose Indium for Your Data Transformation Journey?
As a Databricks consulting partner, Indium brings over a decade of expertise in maximizing enterprise data potential. Leveraging Databricks’ robust, flexible, and scalable platform, our services span the entire data analytics spectrum, ensuring seamless integration and management.
Our homegrown accelerator, ibriX, enhances data integration and management capabilities, accelerating your enterprise’s data transformation. Our services include Databricks consulting, cloud migration, lakehouse development, data engineering on Databricks, and advanced analytics, AI, and ML solutions.
To sum up, working with Indium guarantees a thorough approach to data transformation, utilizing state-of-the-art tools and customized solutions to advance your company.